
At this point, you may have heard of the Google API leak circulating all over the web.
Watch Charles Floate's detailed analysis of Google Leaks.
It was initially shared with SparkToro’s cofounder (and SEOMoz/Moz’s founder) Rank Fishkin. Aside from Rand’s analyses and insights, iPullRank’s Mic King examined the documentation to share his thoughts and ideas about the things found in the leak.
Both are essential resources to help you understand and contextualise the significance of these leaks, how Google ranks websites on SERPs, and how its representatives have said the exact opposite of what is seen from the documentation.
Here are the links to the 4,0 version of the leaked document and a shorter 5.0 version. I’m sharing it so you can also analyse the document for yourself.
Since then, other talented SEOs have investigated the document and added their unique spin. However, aside from the above-mentioned takes on the leaks, the commentaries of others are a mixed bag.
A handful build upon what has already been mentioned and add more value to the conversation (Andrew Ansley’s take comes to mind). Others, conversely, either use the documentation to support their confirmation bias, weaponise it to advance their agendas and ulterior motives, or parrot other SEOs just to make themselves look smart.
The latter is nothing new since SEO is about making money. But by pushing a specific narrative (which isn’t necessarily and entirely false, mind you), they create even more unnecessary confusion, fear, and frustration in the community. This is magnified due to not having a clear resolution to the March 2024 Update and the looming threat of Google AI Overviews (remember these things?).
Whether you’ve delved deep into the leak or not, one fundamental truth should be clear: it's time to distinguish between right and wrong in SEO.
Notice that I didn’t link to the resources above except for the actual documents. This is deliberate because you need to do the legwork yourself. I’m not talking about searching for the links and reading them–I’m referring to analysing the leak yourself and understanding its contents.

So, for this exercise, we’ll use AI to help us make sense of the leak. As mentioned in the SEO Side Hustles 24/25, there’s no excuse for you to be proficient in all areas of SEO–whether it’s on-page, off-page, technical, or even coding. So, even if you only have a basic knowledge and understanding of SEO, the resources available should help you learn and execute everything faster and better.
Also, consider this as a crash course for taking accountability in SEO. If you’ve been deferring to SEO gurus and self-proclaimed experts for the best practices, this is the time to stop this and be your source of information. That means you must do the research from the ground up, whatever it takes.
With these in mind, let’s begin!
Where to Start with Google’s Leaked Document
Use a language learning model (LLM) to read URL links–ChatGPT Premium and Google Gemium Plus let you do this. However, we’ll use ChatGPT to analyse the documents for this exercise
Next, you must refine your prompts to help you analyse the documentation. Your level of knowledge in understanding the document differs from others, so you need to prepare prompts that are on par with your level of understanding. You must be clear with your prompts and know what you want in the document. You can’t just ask AI to summarise everything for you when you don’t know what you want to find there.
That said, we’ll follow this train of thought for our AI prompts:
- Let the LLM explain to us what the documentation is about based on our level of SEO understanding.
- Ask it to identify the top things you should know about the documentation.
- Ask it to elaborate on each point and how it relates to SEO.
- Ask for other things that should be mentioned in its summary. Rinse and repeat!
When asking these queries, it’s important to use the same chat conversion throughout the entire process. Having all your questions about the leaked documentation in the same chat paves the way for more consistent answers.
Also, LLMs, particularly ChatGPT, tend to remember your past queries from previous conversations with them and allow you to manage them. So, to get unbiased answers from the AI (or prevent it from using previous information you entered), it’s best to clear its memories before starting.
Establish Your Starting Point
Ask ChatGPT to help you understand the document (we’ll start with v 0.4.0). Provide information about yourself, i.e., what kind of SEO you are, your knowledge of the page’s contents, etc.

From the explanation above, you already have points of interest you can expand on with your conversation with the AI. However, you may find understanding it difficult because the text is too technical or doesn’t sufficiently present the relationship between the documentation and SEO. In this case, ask questions to help you connect the dots by asking to simplify the answer (re-explaining the text again to an eighth grader) or directly asking what the document’s contents (about the Google Content Warehouse) have to do with SEO:

We now have a clearer path to understanding the document from an SEO perspective. Use the points mentioned in its answers as breadcrumbs to follow to the bottom of the document.

Note that all the answers provided by ChatGPT about the documentation mention Gemini AI repeatedly as a way of “ensuring the content is relevant and engaging.” But looking at the v0.4.0, it doesn’t explicitly mention Gemini AP on the page. That’s why it’s important to cross-reference their answers with the document to ensure that AI isn’t hallucinating or pulling answers out of thin air.

Policing AI vigilantly will be one of the biggest challenges when using it to analyse a complex document like this leak. But you need to commit to it if you want to get the best and correct answers to your queries.
The answer above says that the “Generative AI Models” section has little to do with SEO and more about how its APIs can help you manage the models to produce high-quality content. So, unless you have a proprietary content creation model, this part will be irrelevant to you.
You can continue exploring “Content Quality and Relevance” by asking ChatGPT about output parsers and retrievers, streaming and batching, and others. But for now, we can move on to learning more about the other key aspects mentioned in the document, according to the LLM.
However, there’s a great risk of the LLM trying to interpret things that may or may not be correct. This is magnified when asking about something it initially mentioned (“Structured Data” being a key SEO factor according to the Google Content Warehouse) but doesn’t appear in the document.
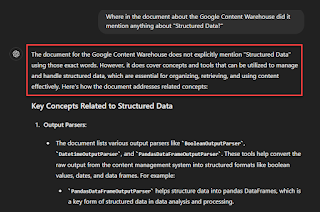
You have no control over this, so it’s really best to manually check if the document explicitly mentions these things and ask AI to rectify its answers.
While this is far from good, at least you know where the LLM’s baseline knowledge is about the document and how it tries to read it. You must remember that it’s a learning language model–hence, the name. You have to collaborate with it to help each other develop an answer that suits your knowledge and understanding of SEO.
Filling in the Blanks
The initial answers ChatGPT provided are only a fraction of what the document is about–you have to keep asking questions to understand it.
However, as we’ve seen above, some of the answers are false due to hallucinations. Other times, it’s pulling information from irrelevant sources.
So, if you want ChatGPT to interpret the page, you must feed it its content. To do this, identify which parts of the document you want the LLM to analyse. For SEO, you want to find words in the attribute relevant to what you specialise in. For instance, if your focus is on content creation, search “blog” on the page to find attributes that mention this term.
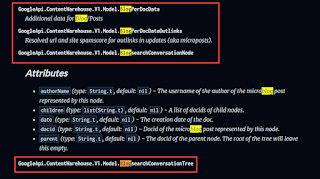
Copy which attribute you want to learn more about and then ask ChatGPT about it.

The answer ChatGPT provided explains how Google considers the blog’s structure and engagement. Ideally, the more organized both variables are, the easier Google can understand what your blog and its posts are about, allowing it to rank and index it high on search results.
Keep doing this on attributes to dig deeper into what each means. One of them talks about the relationship between blog content and outbound links.

Continue doing this for other SEO areas that you can find on the document, like off-page, technical SEO, etc. This will help you understand how Google analyses the pages in its Content Warehouse based on these attributes.
This is the best way to get ChatGPT to help you understand complex documents like this Google leak. That’s why it’s also important to know what you’re looking for to get LLMs to provide answers you’ll understand. On the downside, getting ChatGPT to analyse each attribute will be extremely time-consuming. Make sure to pick your spots and limit your analysis to those that will be relevant to you.
Next Steps
You can take your prompts to include multiple attributes related to each other to make your research faster.
For example, you want to understand what attributes about links are about. To do this, search the document for attributes that mention “link,” compile them, and ask ChatGPT what they mean and their relevance to SEO.

In the example above, I compiled all the mentions of “link” in the attributes and modules and asked ChatGPT to explain what these all mean in the context of SEO. It grouped and organized them according to functionality and explained the importance of each group.

ChatGPT was kind enough to include a summary of SEO insights for the compile modules and attributes to help you understand them.
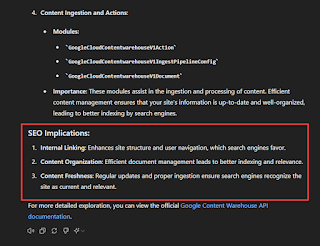
From here, you can ask how each group of attributes and modules play a role in its implications for SEO.

Mind you that not all of the findings you’ll gather from the research will be groundbreaking, nor are they something you don’t already know. At the very least, the APIs confirm what most of us already know about Google and how it processes crawling and indexing the pages for SERPs. It’s up to you to decide where to take your research from here.
Additional Insights
Upon hours of using various LLMs to understand the leaked document, I must say that it’s been a challenge. It wasn’t impossible, as the ideas above should help inspire you to get AI to analyse the document’s various contents, if not inspire you to develop your own process. But this exercise confirmed things
Not All LLMs are the Same
I know this is an obvious answer, but it bears repeating. Each LLM is not only trained using different datasets, but the answers they provide–particularly, the kind of answers they are willing to share with you–are also drastically different.
It’s one thing for an LLM to have limitations, ex. Claude cannot read content from a URL or create images, but it’s another for it to refuse to provide an answer outright. Case in point, Google Gemini.
As with most LLMs, you’ll have to strike up a conversation with the LLM to get an actual answer. Even then, the answers will always be a mixed bag, especially if it can’t answer the original query properly.
AI is Imperfect
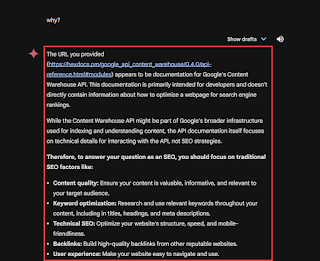
LLMs won’t tell you the answers you want from them, which can be a good thing. For instance, I asked if the documentation has any mentions of backlinks and link building and ChatGPT said otherwise.
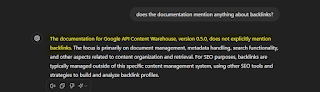
However, when you search the documentation for “link” using your browser’s search feature and ask what ChatGPT this line of text is about, only then will it tell you about the relevance of links in the Google Content Warehouse.
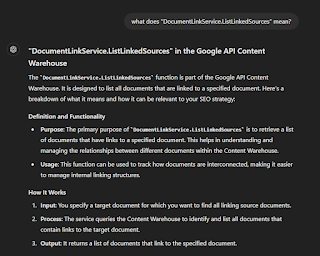
It even went out of its way to create actionable items and use cases on how you can leverage this particular function to power your SEO strategy:

This further shows you that AI is only as intelligent as who it’s talking to. In other words, you must ask LLMs the right questions to get the right answers. As the saying goes, garbage in, garbage out.
Unlike when asking a person with built-in biases and tendencies, LLMs will only throw answers with the data you feed them. If they provide an insufficient answer to your query, keep providing them with additional information and ask them new questions. This helps train LLMs based on your level of knowledge and understanding of the topic.
So, while AI still has limitations, it’s definitely trending in the right direction in terms of helping us comprehend things better and become more proficient SEOs.
But With Your Help, AI is Extremely Powerful
AI is only as diligent as its users. The most important thing about SEO is the desire to learn from new experiences, try new things, and see things through different lenses.
As mentioned, we all have biases when we try to interpret things. The same goes for LLMs, depending on the memories baked into it. But when people and AI work hand in hand to achieve the same goal, you can accomplish many things together in a way that’s objective and based on the text being analysed.
For this to happen, however, you have to lean into your SEO knowledge and develop AI prompts that will help you better understand the attributes and modules in the leaked Google document.
Final Thoughts
Notice that I didn’t share my sentiments about the data provided by ChatGPT above. Because it’s not about what I have to say. Use your thoughts and ideas on SEO and interpret what AI shares with you about the document or any type of text. It’s time to stop letting gurus and so-called experts tell you what is and isn’t SEO. Leverage the available resources to make your own judgments about what needs to be done and how to do it.
To take things to the next level, you must test your ideas and assumptions based on your findings from the document and others. Take action and accountability to determine what works and what doesn’t in this field–the success of SEO as a marketing channel depends on your ability to do this.